

HELLO! I'm Loris, a passionate engineer, researcher, and developer. I work in the fields of Computer Vision and Deep Learning. I have published research on the topics of explainable AI, adversarial ML, multi-modal LLMs, and biomedical imaging. Welcome to my portfolio, where you can explore my activities and publications.
I am a Ph.D. student at Politecnico di Milano, where I obtained my M.Sc. summa cum laude in Dec. 2020. Before my Ph.D., I have also spent one year as research assistant. During these years in academia, I have been doing research in Computer Vision, specifically Explainable Artificial Intelligence and Adversarial Machine Learning, taking the role of principal investigator in a variety of foundational and applied research projects. I have also been active as a teaching assistant for computer science and deep learning courses at my university.
Publications
Pattern Recognition, 2023
BMVC, 2022
IJCNN, 2024
ISBI, 2024
ICIP, 2024
Arxiv, 2024
Industry
Gilardoni S.p.A.
Danieli S.p.A.
Capable.Design
Ikonisys Inc.
vision@polimi
Meccanica del Sarca S.p.A.

Deep Neural Networks (DNNs) are susceptible to adversarial examples. These take the form of small perturbations applied to the model’s input which lead to incorrect predictions. Most of the literature, however, focuses on attacks to digital images, which are by design not deployable to physical targets. Consequently, it is hard to assess how dangerous these attacks are to real world systems such as autonomous vehicles. In this work, we present Adversarial Scratches, a novel attack which is designed to be deployable to physical targets. We leverage Bézier curves to reduce the dimension of the search space and to constraint the attack to a specific location. We test the proposed attack in several scenarios, and show that Adversarial Scratches achieve higher fooling rate than other deployable state-of-the-art methods, while requiring significantly fewer queries and modifying very few pixels.
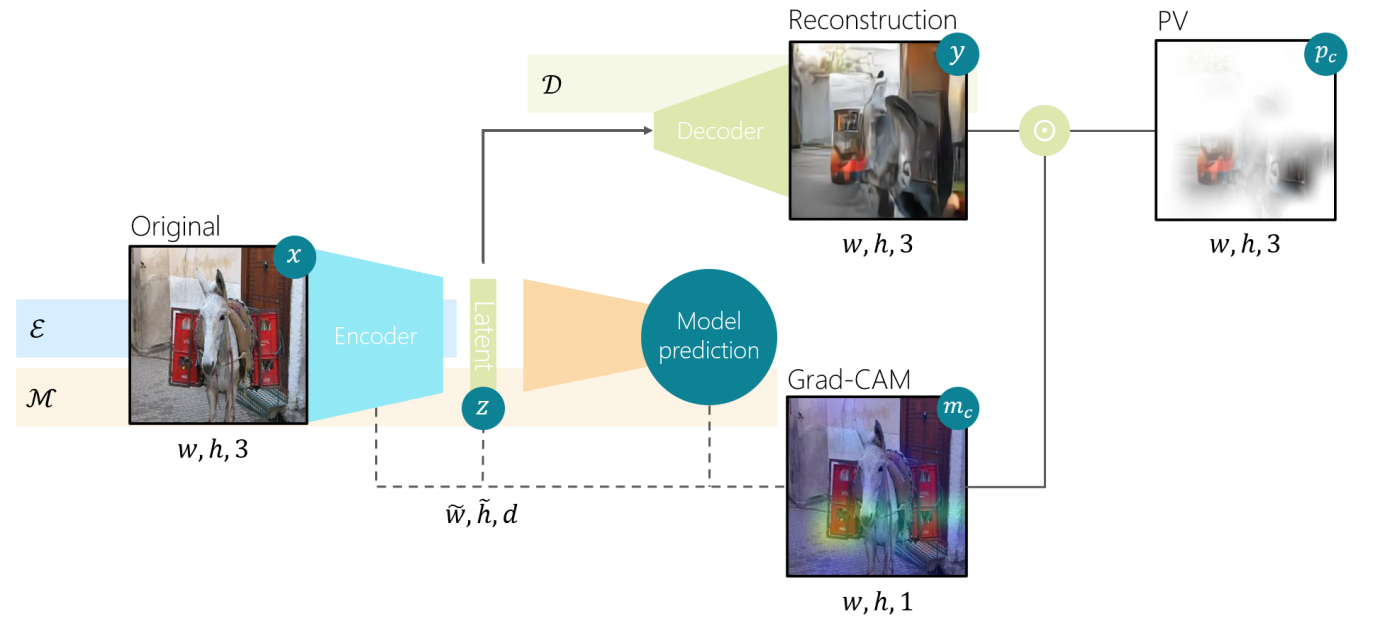
Current research in the field of explainable AI has given rise to various perturbation or gradient-based saliency maps. For images, these techniques fail to fully capture and convey the semantic information needed to elucidate why the model makes the predictions it does. In this work, we develop a new form of explanation that is radically different in nature from current explanation methods, such as Grad-CAM. Perception visualization provides a visual representation of what the DNN perceives in the input image by depicting what visual patterns the latent representation corresponds to. Visualizations are obtained through a reconstruction model that inverts the encoded features, such that the parameters and predictions of the original models are not modified. Results of our user study demonstrate that humans can better understand and predict the system’s decisions when perception visualizations are available, thus easing the debugging and deployment of deep models as trusted systems.

CLIP has shown impressive performance on a variety of tasks, yet, its inherently opaque architecture may hinder the application of models employing CLIP as backbone, especially in fields where trust and model explainability are imperative. Previously available explanations such as saliency maps can only be computed to explain classes relevant to the end task, often smaller in scope than the backbone training classes.In the context of models implementing CLIP as their vision backbone, a substantial portion of the information embedded within the learned representations is thus left unexplained. In this work, we propose Concept Visualization (ConVis), a novel saliency methodology that explains the CLIP embedding of an image by exploiting the multi-modal nature of the embeddings. ConVis makes use of lexical information from WordNet to compute task-agnostic Saliency Maps for any concept, not limited to concepts the end model was trained on. We validate our use of WordNet via an out of distribution detection experiment, and test ConVis on an object localization benchmark, showing that Concept Visualizations correctly identify and localize the image's semantic content. Additionally, we perform a user study demonstrating that our methodology can give users insight on the model's functioning.
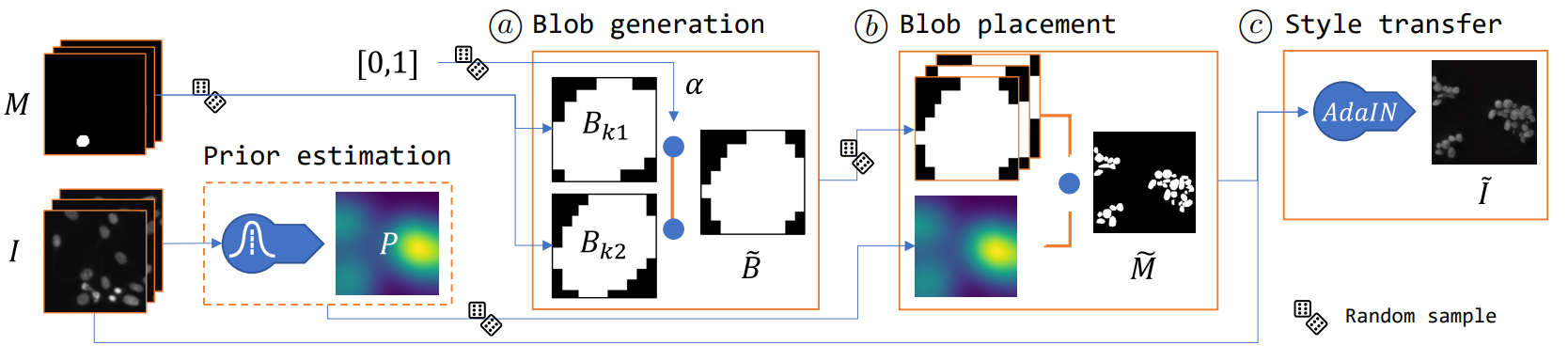
Deep Learning models have been successfully applied to many applications including biomedical cell segmentation and classification in histological images. These models require large amounts of annotated data which might not always be available, especially in the medical field where annotations are scarce and expensive. To overcome this limitation, we propose a novel pipeline for generating synthetic datasets for cell segmentation. Given only a handful of annotated images, our method generates a large dataset of images which can be used to effectively train DL instance segmentation models. Our solution is designed to generate cells of realistic shapes and placement by allowing experts to incorporate domain knowledge during the generation of the dataset.
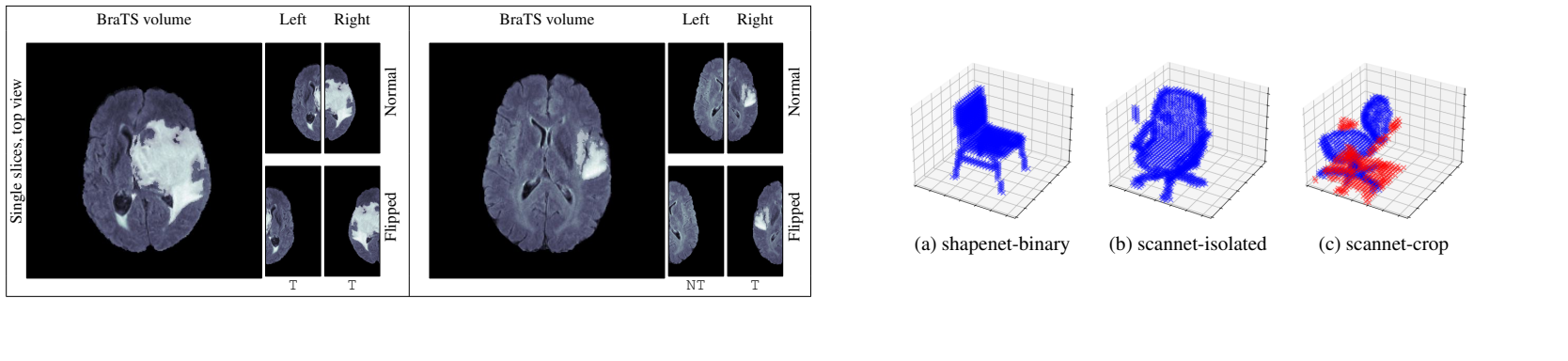
3D CNNs have shown impressive performance in biomedical imaging. In these critical settings, explaining the model's decisions is fundamental. Despite recent advances in Explainable Artificial Intelligence, however, little effort has been devoted to explaining 3D CNNs, and many works explain these models via inadequate extensions of 2D saliency methods. One fundamental limitation to the development of 3D saliency methods is the lack of a benchmark to quantitatively assess them on 3D data. To address this issue, we propose SE3D: a framework for Saliency method Evaluation in 3D imaging. We propose modifications to ShapeNet, ScanNet, and BraTS datasets, and evaluation metrics to assess saliency methods for 3D CNNs. We evaluate both state-of-the-art saliency methods designed for 3D data and extensions of popular 2D saliency methods to 3D. Our experiments show that 3D saliency methods do not provide explanations of sufficient quality, and that there is margin for future improvements and safer applications of 3D CNNs in critical fields.
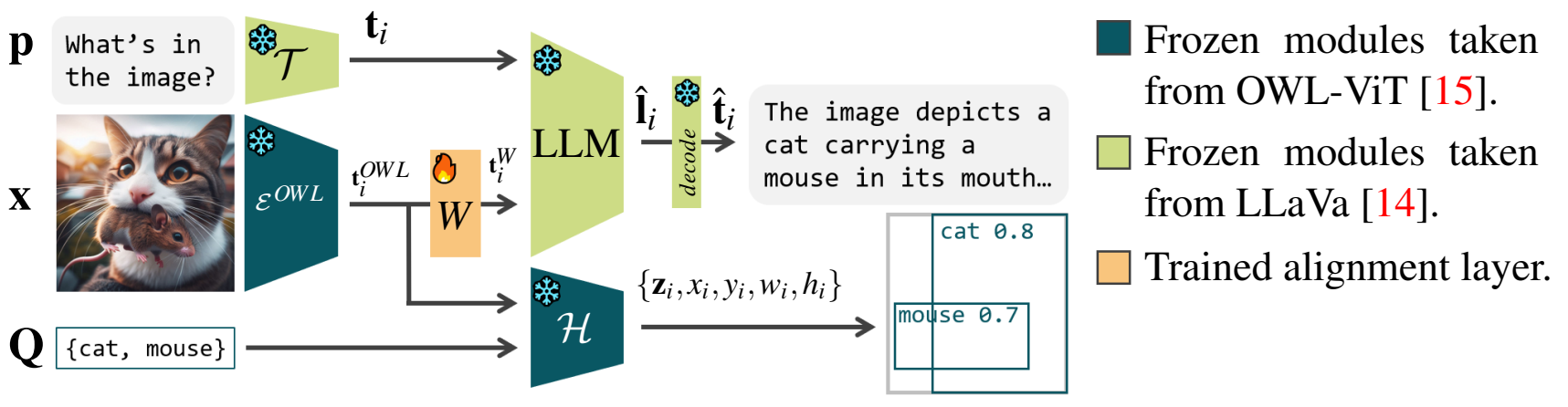
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in understanding and generating content across various modalities, such as images and text. However, their interpretability remains a challenge, hindering their adoption in critical applications. This research proposes a novel approach to enhance the interpretability of MLLMs by focusing on the image embedding component. We combine an open-world localization model with a MLLM, thus creating a new architecture able to simultaneously produce text and object localization outputs from the same vision embedding. The proposed architecture greatly promotes interpretability, enabling us to design a novel saliency map to explain any output token, to identify model hallucinations, and to assess model biases through semantic adversarial perturbations.

Gilardoni S.p.A. develops X-Ray scanners for industrial applications. We have developed an application to detect and categorize defects in metal components from the output X-Ray image. The application employs Machine Learning techniques to cluster and classify alterations in the metal structure.

Danieli S.p.A. develops and operates steel tube manufacturing plants. In one production stage, a steel tube is automatically inserted into a mold by a mandrel. If the tube's position is incorrect, this can cause a catastrophic failure of the plant, with great economi cost and risk to the operators. We have developed a camera system to analyze in real time the position of the tube with millimeter precision. The system enables to raise an alarm if the tube is not positioned correctly, thus avoiding failures. The system has been validated through a digital twin reconstruction of the plant and camera system.

We have developed adversarial patterns in collaboration with Capable.Design that can be knitted on garments to avoid recognition by person identification systems. The patterns are developed to be robust to different views and to be appealing in terms of color and shapes. A patent has been submitted for the developed patterns.

Ikonisys Inc. develops histological imaging equipment. We have developed a Deep Learning system to segment cells in fluorescence images based on Faster-RCNN and deployed it to Ikonisys' machines.

We have developed a system for 3D template matching able to identify all instances of hundreds of planar templates in an image. The system can identify objects such as boxes, and thus can be employed in supermarkets for shelf analysis.
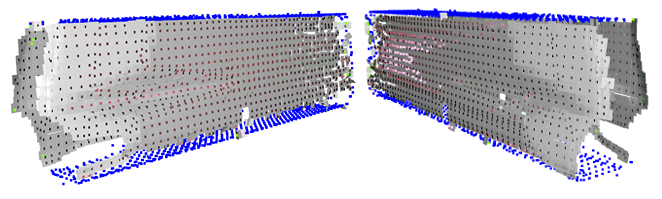
We have developed a camera and laser system to automatically measure the dimensions of a metal component for quality assurance. A point cloud is obtained from the system, which is then compared to a template to verify compliance with the specifications.